You are viewing documentation for Kubernetes version: v1.20
Kubernetes v1.20 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date documentation, see the latest version.
Introducing PodTopologySpread
Author: Wei Huang (IBM), Aldo Culquicondor (Google)
Managing Pods distribution across a cluster is hard. The well-known Kubernetes features for Pod affinity and anti-affinity, allow some control of Pod placement in different topologies. However, these features only resolve part of Pods distribution use cases: either place unlimited Pods to a single topology, or disallow two Pods to co-locate in the same topology. In between these two extreme cases, there is a common need to distribute the Pods evenly across the topologies, so as to achieve better cluster utilization and high availability of applications.
The PodTopologySpread scheduling plugin (originally proposed as EvenPodsSpread) was designed to fill that gap. We promoted it to beta in 1.18.
API changes
A new field topologySpreadConstraints is introduced in the Pod's spec API:
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
As this API is embedded in Pod's spec, you can use this feature in all the high-level workload APIs, such as Deployment, DaemonSet, StatefulSet, etc.
Let's see an example of a cluster to understand this API.
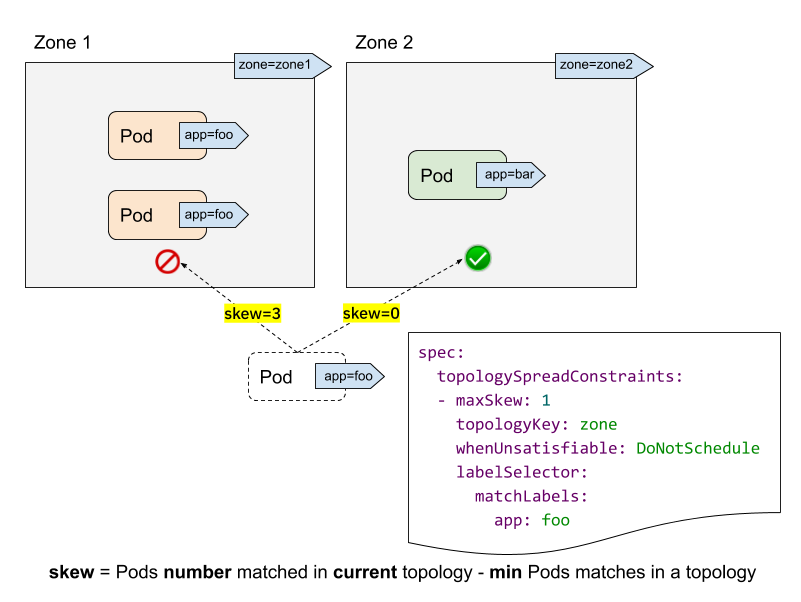
- labelSelector is used to find matching Pods. For each topology, we count the number of Pods that match this label selector. In the above example, given the labelSelector as "app: foo", the matching number in "zone1" is 2; while the number in "zone2" is 0.
- topologyKey is the key that defines a topology in the Nodes' labels. In the above example, some Nodes are grouped into "zone1" if they have the label "zone=zone1" label; while other ones are grouped into "zone2".
- maxSkew describes the maximum degree to which Pods can be unevenly
distributed. In the above example:
- if we put the incoming Pod to "zone1", the skew on "zone1" will become 3 (3 Pods matched in "zone1"; global minimum of 0 Pods matched on "zone2"), which violates the "maxSkew: 1" constraint.
- if the incoming Pod is placed to "zone2", the skew on "zone2" is 0 (1 Pod matched in "zone2"; global minimum of 1 Pod matched on "zone2" itself), which satisfies the "maxSkew: 1" constraint. Note that the skew is calculated per each qualified Node, instead of a global skew.
- whenUnsatisfiable specifies, when "maxSkew" can't be satisfied, what
action should be taken:
DoNotSchedule(default) tells the scheduler not to schedule it. It's a hard constraint.ScheduleAnywaytells the scheduler to still schedule it while prioritizing Nodes that reduce the skew. It's a soft constraint.
Advanced usage
As the feature name "PodTopologySpread" implies, the basic usage of this feature is to run your workload with an absolute even manner (maxSkew=1), or relatively even manner (maxSkew>=2). See the official document for more details.
In addition to this basic usage, there are some advanced usage examples that enable your workloads to benefit on high availability and cluster utilization.
Usage along with NodeSelector / NodeAffinity
You may have found that we didn't have a "topologyValues" field to limit which topologies the Pods are going to be scheduled to. By default, it is going to search all Nodes and group them by "topologyKey". Sometimes this may not be the ideal case. For instance, suppose there is a cluster with Nodes tagged with "env=prod", "env=staging" and "env=qa", and now you want to evenly place Pods to the "qa" environment across zones, is it possible?
The answer is yes. You can leverage the NodeSelector or NodeAffinity API spec. Under the hood, the PodTopologySpread feature will honor that and calculate the spread constraints among the nodes that satisfy the selectors.
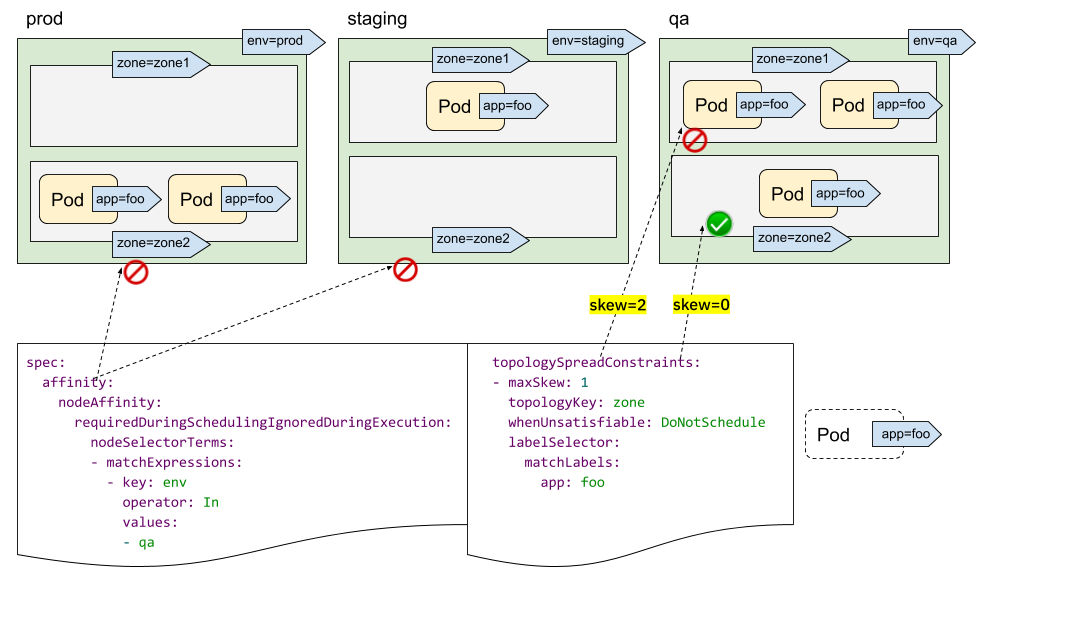
As illustrated above, you can specify spec.affinity.nodeAffinity to limit the
"searching scope" to be "qa" environment, and within that scope, the Pod will be
scheduled to one zone which satisfies the topologySpreadConstraints. In this
case, it's "zone2".
Multiple TopologySpreadConstraints
It's intuitive to understand how one single TopologySpreadConstraint works. What's the case for multiple TopologySpreadConstraints? Internally, each TopologySpreadConstraint is calculated independently, and the result sets will be merged to generate the eventual result set - i.e., suitable Nodes.
In the following example, we want to schedule a Pod to a cluster with 2 requirements at the same time:
- place the Pod evenly with Pods across zones
- place the Pod evenly with Pods across nodes
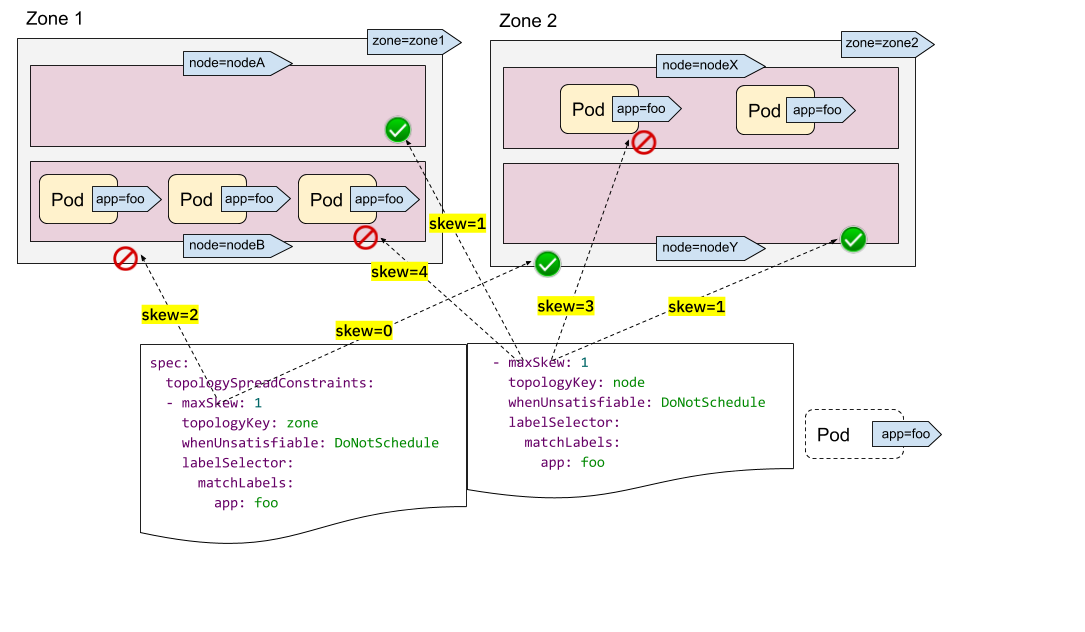
For the first constraint, there are 3 Pods in zone1 and 2 Pods in zone2, so the incoming Pod can be only put to zone2 to satisfy the "maxSkew=1" constraint. In other words, the result set is nodeX and nodeY.
For the second constraint, there are too many Pods in nodeB and nodeX, so the incoming Pod can be only put to nodeA and nodeY.
Now we can conclude the only qualified Node is nodeY - from the intersection of the sets {nodeX, nodeY} (from the first constraint) and {nodeA, nodeY} (from the second constraint).
Multiple TopologySpreadConstraints is powerful, but be sure to understand the difference with the preceding "NodeSelector/NodeAffinity" example: one is to calculate result set independently and then interjoined; while the other is to calculate topologySpreadConstraints based on the filtering results of node constraints.
Instead of using "hard" constraints in all topologySpreadConstraints, you can also combine using "hard" constraints and "soft" constraints to adhere to more diverse cluster situations.
Note: If two TopologySpreadConstraints are being applied for the same {topologyKey, whenUnsatisfiable} tuple, the Pod creation will be blocked returning a validation error.
PodTopologySpread defaults
PodTopologySpread is a Pod level API. As such, to use the feature, workload
authors need to be aware of the underlying topology of the cluster, and then
specify proper topologySpreadConstraints in the Pod spec for every workload.
While the Pod-level API gives the most flexibility it is also possible to
specify cluster-level defaults.
The default PodTopologySpread constraints allow you to specify spreading for all the workloads in the cluster, tailored for its topology. The constraints can be specified by an operator/admin as PodTopologySpread plugin arguments in the scheduling profile configuration API when starting kube-scheduler.
A sample configuration could look like this:
apiVersion: kubescheduler.config.k8s.io/v1alpha2
kind: KubeSchedulerConfiguration
profiles:
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: example.com/rack
whenUnsatisfiable: ScheduleAnyway
When configuring default constraints, label selectors must be left empty. kube-scheduler will deduce the label selectors from the membership of the Pod to Services, ReplicationControllers, ReplicaSets or StatefulSets. Pods can always override the default constraints by providing their own through the PodSpec.
Note: When using default PodTopologySpread constraints, it is recommended to disable the old DefaultTopologySpread plugin.
Wrap-up
PodTopologySpread allows you to define spreading constraints for your workloads with a flexible and expressive Pod-level API. In the past, workload authors used Pod AntiAffinity rules to force or hint the scheduler to run a single Pod per topology domain. In contrast, the new PodTopologySpread constraints allow Pods to specify skew levels that can be required (hard) or desired (soft). The feature can be paired with Node selectors and Node affinity to limit the spreading to specific domains. Pod spreading constraints can be defined for different topologies such as hostnames, zones, regions, racks, etc.
Lastly, cluster operators can define default constraints to be applied to all Pods. This way, Pods don't need to be aware of the underlying topology of the cluster.