This the multi-page printable view of this section. Click here to print.
Architettura di Kubernetes
1 - Comunicazione Control Plane - Nodo
Questo documento cataloga le connessioni tra il piano di controllo (control-plane), in realtà l'apiserver, e il cluster Kubernetes. L'intento è di consentire agli utenti di personalizzare la loro installazione per rafforzare la configurazione di rete affinché il cluster possa essere eseguito su una rete pubblica (o su IP completamente pubblici resi disponibili da un fornitore di servizi cloud).
Dal Nodo al control-plane
Kubernetes adotta un pattern per le API di tipo "hub-and-spoke". Tutte le chiamate delle API eseguite sui vari nodi sono effettuate verso l'apiserver (nessuno degli altri componenti principali è progettato per esporre servizi remoti). L'apiserver è configurato per l'ascolto di connessioni remote su una porta HTTPS protetta (443) con una o più forme di autenticazioni client abilitate. Si dovrebbero abilitare una o più forme di autorizzazioni, in particolare nel caso in cui siano ammesse richieste anonime o token legati ad un account di servizio (service account).
Il certificato pubblico (public root certificate) relativo al cluster corrente deve essere fornito ai vari nodi di modo che questi possano connettersi in modo sicuro all'apiserver insieme alle credenziali valide per uno specifico client. Ad esempio, nella configurazione predefinita di un cluster GKE, le credenziali del client fornite al kubelet hanno la forma di un certificato client. Si veda inizializzazione TLS del kubelet TLS per la fornitura automatica dei certificati client al kubelet.
I Pod che desiderano connettersi all'apiserver possono farlo in modo sicuro sfruttando un account di servizio in modo che Kubernetes inserisca automaticamente il certificato pubblico di radice e un token valido al portatore (bearer token) all'interno Pod quando questo viene istanziato.
In tutti i namespace è configurato un Service con nome kubernetes con un indirizzo IP virtuale che viene reindirizzato (tramite kube-proxy) all'endpoint HTTPS dell'apiserver.
Anche i componenti del piano d controllo comunicano con l'apiserver del cluster su di una porta sicura esposta da quest'ultimo.
Di conseguenza, la modalità operativa predefinita per le connessioni dai nodi e dai Pod in esecuzione sui nodi verso il control-plane è protetta da un'impostazione predefinita e può essere eseguita su reti non sicure e/o pubbliche.
Dal control-plane al nodo
Esistono due percorsi di comunicazione principali dal control-plane (apiserver) verso i nodi. Il primo è dall'apiserver verso il processo kubelet in esecuzione su ogni nodo nel cluster. Il secondo è dall'apiserver a ciascun nodo, Pod, o servizio attraverso la funzionalità proxy dell'apiserver.
Dall'apiserver al kubelet
Le connessioni dall'apiserver al kubelet vengono utilizzate per:
- Prendere i log relativi ai vari Pod.
- Collegarsi (attraverso kubectl) ai Pod in esecuzione.
- Fornire la funzionalità di port-forwarding per i kubelet.
Queste connessioni terminano all'endpoint HTTPS del kubelet. Di default, l'apiserver non verifica il certificato servito dal kubelet, il che rende la connessione soggetta ad attacchi man-in-the-middle, e tale da essere considerato non sicuro (unsafe) se eseguito su reti non protette e/o pubbliche.
Per verificare questa connessione, si utilizzi il parametro --kubelet-certificate-authority al fine di fornire all'apiserver un insieme di certificati radice da utilizzare per verificare il
il certificato servito dal kubelet.
Se questo non è possibile, si usi un tunnel SSH tra l'apiserver e il kubelet, se richiesto, per evitare il collegamento su una rete non protetta o pubblica.
In fine, l'autenticazione e/o l'autorizzazione del kubelet dovrebbe essere abilitate per proteggere le API esposte dal kubelet.
Dall'apiserver ai nodi, Pod, e servizi
Le connessioni dall'apiserver verso un nodo, Pod o servizio avvengono in modalità predefinita su semplice connessione HTTP e quindi non sono né autenticate né criptata. Queste connessioni possono essere eseguite su una connessione HTTPS sicura mediante il prefisso https: al nodo, Pod o nome del servizio nell'URL dell'API, ma non valideranno il certificato fornito dall'endpoint HTTPS né forniranno le credenziali del client così anche se la connessione verrà criptata, non fornirà alcuna garanzia di integrità. Non è attualmente sicuro eseguire queste connessioni su reti non protette e/o pubbliche.
I tunnel SSH
Kubernetes supporta i tunnel SSH per proteggere la comunicazione tra il control-plane e i nodi. In questa configurazione, l'apiserver inizializza un tunnel SSH con ciascun nodo del cluster (collegandosi al server SSH in ascolto sulla porta 22) e fa passare tutto il traffico verso il kubelet, il nodo, il Pod, o il servizio attraverso questo tunnel. Questo tunnel assicura che il traffico non sia esposto al di fuori della rete su cui sono in esecuzioni i vari nodi.
I tunnel SSH sono al momento deprecati ovvero non dovrebbero essere utilizzati a meno che ci siano delle esigenze particolari. Il servizio Konnectivity è pensato per rimpiazzare questo canale di comunicazione.
Il servizio Konnectivity
Kubernetes v1.18 [beta]Come rimpiazzo dei tunnel SSH, il servizio Konnectivity fornisce un proxy a livello TCP per la comunicazione tra il control-plane e il cluster. Il servizio Konnectivity consiste in due parti: il Konnectivity server e gli agenti Konnectivity, in esecuzione rispettivamente sul control-plane e sui vari nodi. Gli agenti Konnectivity inizializzano le connessioni verso il server Konnectivity e mantengono le connessioni di rete. Una volta abilitato il servizio Konnectivity, tutto il traffico tra il control-plane e i nodi passa attraverso queste connessioni.
Si può fare riferimento al tutorial per il servizio Konnectivity per configurare il servizio Konnectivity all'interno del cluster
2 - Concetti alla base del Cloud Controller Manager
Il concetto di CCM (cloud controller manager), da non confondere con il binario, è stato originariamente creato per consentire di sviluppare Kubernetes indipendentemente dall'implementazione dello specifico cloud provider. Il cloud controller manager viene eseguito insieme ad altri componenti principali come il Kubernetes controller manager, il server API e lo scheduler. Può anche essere avviato come addon di Kubernetes, nel qual caso viene eseguito su Kubernetes.
Il design del cloud controller manager è basato su un meccanismo di plug-in che consente ai nuovi provider cloud di integrarsi facilmente con Kubernetes creando un plug-in. Sono in atto programmi per l'aggiunta di nuovi provider di cloud su Kubernetes e per la migrazione dei provider che usano il vecchio metodo a questo nuovo metodo.
Questo documento discute i concetti alla base del cloud controller manager e fornisce dettagli sulle funzioni associate.
Ecco l'architettura di un cluster Kubernetes senza il gestore del controller cloud:
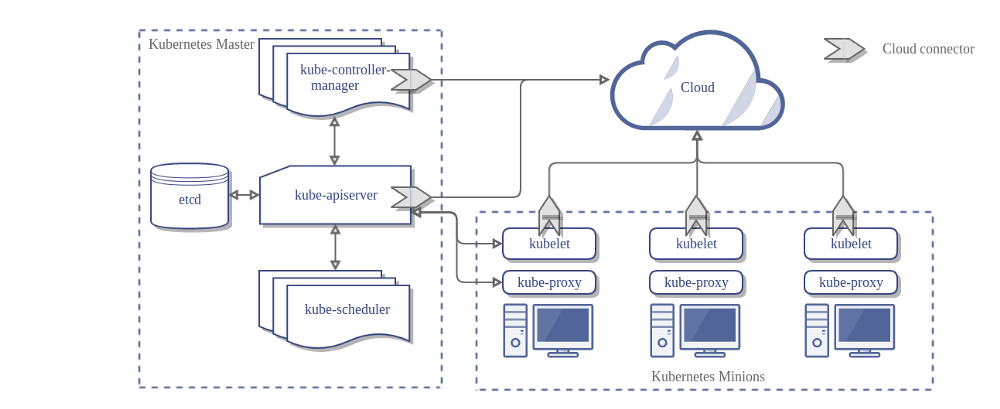
Architettura
Nel diagramma precedente, Kubernetes e il provider cloud sono integrati attraverso diversi componenti:
- Kubelet
- Kubernetes controller manager
- Kubernetes API server
Il CCM consolida tutta la logica dipendente dal cloud presente nei tre componenti precedenti, per creare un singolo punto di integrazione con il cloud. La nuova architettura con il CCM si presenta così:
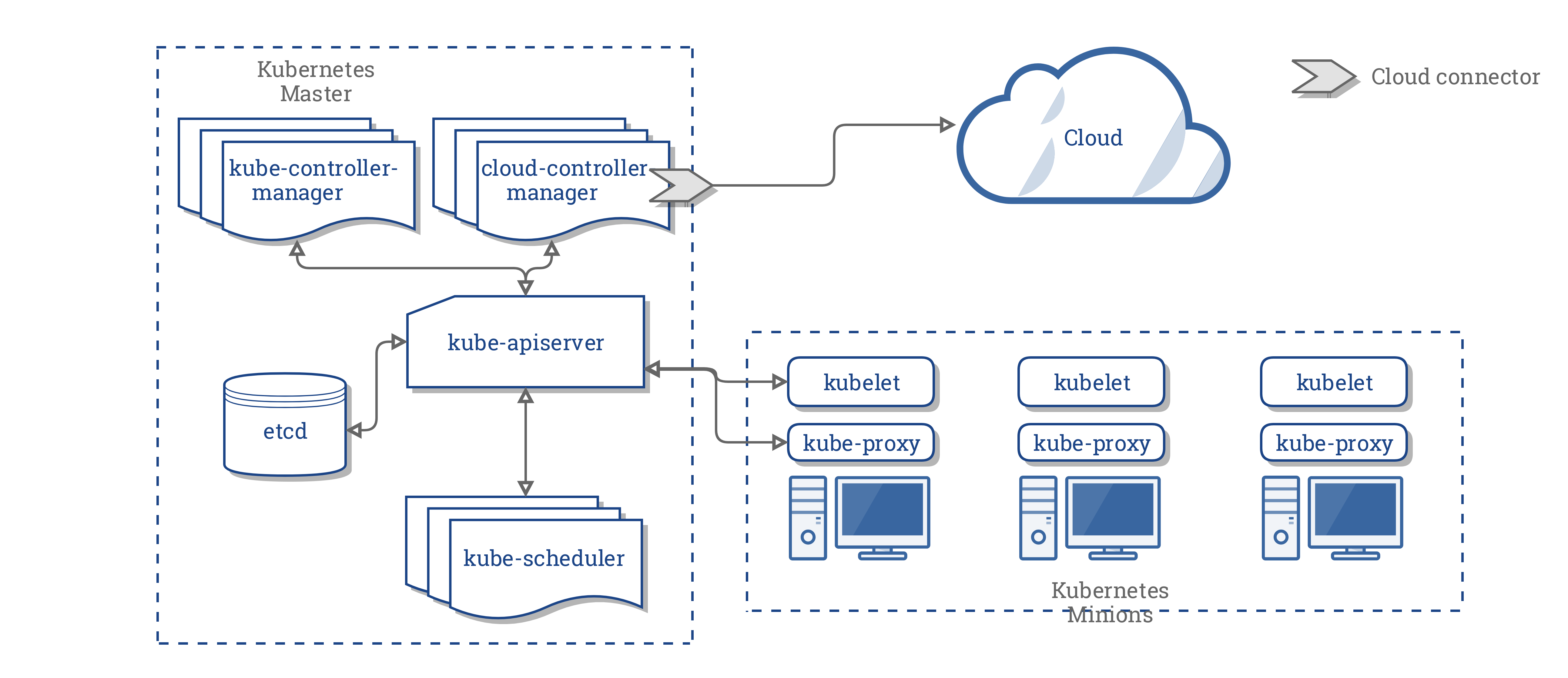
Componenti del CCM
Il CCM divide alcune funzionalità del Kubernetes controller manager (KCM) e le esegue in un differente processo. In particolare, toglie dal KCM le integrazioni con il cloud specifico. Il KCM ha i seguenti controller che dipendono dal cloud specifico:
- Node controller
- Volume controller
- Route controller
- Service controller
Nella versione 1.9, il CCM esegue i seguenti controller dall'elenco precedente:
- Node controller
- Route controller
- Service controller
Nota: È stato deliberatamente deciso di non spostare il Volume controller nel CCM. Data la complessità del Volume controller e gli sforzi già fatti per astrarre le logiche specifiche dei singoli fornitori, è stato deciso che il Volume controller non verrà spostato nel CCM.
Il piano originale per supportare i volumi utilizzando il CCM era di utilizzare Flex per supportare volumi collegabili. Tuttavia, una implementazione parallela, nota come CSI è stata designata per sostituire Flex.
Considerando queste evoluzioni, abbiamo deciso di adottare un approccio intermedio finché il CSI non è pronto.
Funzioni del CCM
Il CCM eredita le sue funzioni da componenti di Kubernetes che dipendono da uno specifico provider di cloud. Questa sezione è strutturata sulla base di tali componenti.
1. Kubernetes controller manager
La maggior parte delle funzioni del CCM deriva dal KCM. Come menzionato nella sezione precedente, CCM esegue i seguenti cicli di controllo:
- Node controller
- Route controller
- Service controller
Node controller
Il Node controller è responsabile per l'inizializzazione di un nodo ottenendo informazioni sui nodi in esecuzione nel cluster dal provider cloud. Il controller del nodo esegue le seguenti funzioni:
- Inizializzare un nodo con le label zone/region specifiche per il cloud in uso.
- Inizializzare un nodo con le specifiche, ad esempio, tipo e dimensione specifiche del cloud in uso.
- Ottenere gli indirizzi di rete del nodo e l'hostname.
- Nel caso in cui un nodo non risponda, controlla il cloud per vedere se il nodo è stato cancellato dal cloud. Se il nodo è stato eliminato dal cloud, elimina l'oggetto Nodo di Kubernetes.
Route controller
Il Route controller è responsabile della configurazione delle route nel cloud in modo che i container su nodi differenti del cluster Kubernetes possano comunicare tra loro. Il Route controller è utilizzabile solo dai cluster su Google Compute Engine.
Service Controller
Il Service Controller rimane in ascolto per eventi di creazione, aggiornamento ed eliminazione di servizi. In base allo stato attuale dei servizi in Kubernetes, configura i bilanciatori di carico forniti dal cloud (come gli ELB, i Google LB, o gli Oracle Cloud Infrastructure LB) per riflettere lo stato dei servizi in Kubernetes. Inoltre, assicura che i back-end dei bilanciatori di carico forniti dal cloud siano aggiornati.
2. Kubelet
Il Node Controller contiene l'implementazione dipendente dal cloud della kubelet. Prima dell'introduzione del CCM, la kubelet era responsabile dell'inizializzazione di un nodo con dettagli dipendenti dallo specifico cloud come gli indirizzi IP, le label region/zone e le informazioni sul tipo di istanza. L'introduzione del CCM ha spostato questa operazione di inizializzazione dalla kubelet al CCM.
In questo nuovo modello, la kubelet inizializza un nodo senza informazioni specifiche del cloud. Tuttavia, aggiunge un blocco al nodo appena creato che rende il nodo non selezionabile per eseguire container finché il CCM non inizializza il nodo con le informazioni specifiche del cloud. Il CCM rimuove quindi questo blocco.
Sistema a plug-in
Il cloud controller manager utilizza le interfacce di Go per consentire l'implementazione di implementazioni di qualsiasi cloud. In particolare, utilizza l'interfaccia CloudProvider definita qui.
L'implementazione dei quattro controller generici evidenziati sopra, alcune strutture, l'interfaccia cloudprovider condivisa rimarranno nel core di Kubernetes. Le implementazioni specifiche per i vari cloud saranno costruite al di fuori del core e implementeranno le interfacce definite nel core.
Per ulteriori informazioni sullo sviluppo di plug-in, consultare Developing Cloud Controller Manager.
Autorizzazione
Questa sezione dettaglia l'accesso richiesto dal CCM sui vari API objects per eseguire le sue operazioni.
Node controller
Il Node controller funziona solo con oggetti di tipo Node. Richiede l'accesso completo per ottenere, elencare, creare, aggiornare, applicare patch, guardare ed eliminare oggetti di tipo Node.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Route controller
Il Route controller ascolta la creazione dell'oggetto Node e configura le rotte in modo appropriato. Richiede l'accesso in lettura agli oggetti di tipo Node.
v1/Node:
- Get
Service controller
Il Service controller resta in ascolto per eventi di creazione, aggiornamento ed eliminazione di oggetti di tipo Servizi, e configura gli endpoint per tali Servizi in modo appropriato.
Per accedere ai Servizi, è necessario il permesso per list e watch. Per aggiornare i Servizi, sono necessari i permessi patch e update.
Per impostare gli endpoint per i Servizi, richiede i permessi create, list, get, watch, e update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Others
L'implementazione del core di CCM richiede l'accesso per creare eventi e, per garantire operazioni sicure, richiede l'accesso per creare ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
L'RBAC ClusterRole per il CCM ha il seguente aspetto:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Vendor Implementations
I seguenti fornitori di cloud hanno una implementazione di CCM:
Cluster Administration
Le istruzioni complete per la configurazione e l'esecuzione del CCM sono fornite qui.
3 - Controller
Nella robotica e nell'automazione, un circuito di controllo (control loop) è un un'iterazione senza soluzione di continuità che regola lo stato di un sistema.
Ecco un esempio di un circuito di controllo: il termostato di una stanza.
Quando viene impostata la temperatura, si definisce attraverso il termostato lo stato desiderato. L'attuale temperatura nella stanza è invece lo stato corrente. Il termostato agisce per portare lo stato corrente il più vicino possibile allo stato desiderato accendendo e spegnendo le apparecchiature.
In Kubernetes, i controller sono circuiti di controllo che osservano lo stato del cluster, e apportano o richiedono modifiche quando necessario. Ogni controller prova a portare lo stato corrente del cluster verso lo stato desiderato.Il modello del controller
Un controller monitora almeno una tipo di risorsa registrata in Kubernetes. Questi oggetti hanno una proprietà chiamata spec (specifica) che rappresenta lo stato desiderato. Il o i controller per quella risorsa sono responsabili di mantenere lo stato corrente il più simile possibile rispetto allo stato desiderato.
Il controller potrebbe eseguire l'azione relativa alla risorsa in questione da sé; più comunemente, in Kubernetes, un controller invia messaggi all'API server che a sua volta li rende disponibili ad altri componenti nel cluster. Di seguito troverete esempi per questo scenario.
Controllo attraverso l'API server
Il Job controller è un esempio di un controller nativo in Kubernetes. I controller nativi gestiscono lo stato interagendo con l'API server presente nel cluster.
Il Job è una risorsa di Kubernetes che lancia uno o più Pod per eseguire un lavoro (task) e poi fermarsi.
(Una volta che è stato schedulato, un oggetto Pod diventa parte dello stato desisderato di un dato kubelet).
Quando il Job controller vede un nuovo lavoro da svolgere si assicura che, da qualche parte nel cluster, i kubelet anche sparsi su più nodi eseguano il numero corretto di Pod necessari per eseguire il lavoro richiesto. Il Job controller non esegue direttamente alcun Pod o container bensì chiede all'API server di creare o rimuovere i Pod. Altri componenti appartenenti al control plane reagiscono in base alle nuove informazioni (ci sono nuovi Pod da creare e gestire) e cooperano al completamento del job.
Dopo che un nuovo Job è stato creato, lo stato desiderato per quel Job è il suo completamento. Il Job controller fa sì che lo stato corrente per quel Job sia il più vicino possibile allo stato desiderato: creare Pod che eseguano il lavoro che deve essere effettuato attraverso il Job, così che il Job sia prossimo al completamento.
I controller aggiornano anche gli oggetti che hanno configurato. Ad esempio: una volta che il lavoro relativo ad un dato Job è stato completato, il Job controller aggiorna l'oggetto Job segnandolo come Finished.
(Questo è simile allo scenario del termostato che spegne un certo led per indicare che ora la stanza ha raggiungo la temperatura impostata)
Controllo diretto
A differenza del Job, alcuni controller devono eseguire delle modifiche a parti esterne al cluster.
Per esempio, se viene usato un circuito di controllo per assicurare che ci sia un numero sufficiente di Nodi nel cluster, allora il controller ha bisogno che qualcosa al di fuori del cluster configuri i nuovi Nodi quando sarà necessario.
I controller che interagiscono con un sistema esterno trovano il loro stato desiderato attraverso l'API server, quindi comunicano direttamente con un sistema esterno per portare il loro stato corrente più in linea possibile con lo stato desiderato
(In realtà c'è un controller che scala orizzontalmente i nodi nel cluster. Vedi Cluster autoscaling).
Stato desiderato versus corrente
Kubernetes ha una visione cloud-native dei sistemi, ed è in grado di gestire continue modifiche.
Il cluster viene modificato continuamente durante la sua attività ed il circuito di controllo è in grado di risolvere automaticamente i possibili guasti.
Fino a che i controller del cluster sono in funzione ed in grado di apportare le dovute modifiche, non è rilevante che lo stato complessivo del cluster sia o meno stabile.
Progettazione
Come cardine della sua progettazione, Kubernetes usa vari controller ognuno dei quali è responsabile per un particolare aspetto dello stato del cluster. Più comunemente, un dato circuito di controllo (controller) usa un tipo di risorsa per il suo stato desiderato, ed utilizza anche risorse di altro tipo per raggiungere questo stato desiderato. Per esempio il Job controller tiene traccia degli oggetti di tipo Job (per scoprire nuove attività da eseguire) e degli oggetti di tipo Pod (questi ultimi usati per eseguire i Job, e quindi per controllare quando il loro lavoro è terminato). In questo caso, qualcos'altro crea i Job, mentre il Job controller crea i Pod.
È utile avere semplici controller piuttosto che un unico, monolitico, circuito di controllo. I controller possono guastarsi, quindi Kubernetes è stato disegnato per gestire questa eventualità.
Nota:Ci possono essere diversi controller che creato o aggiornano lo stesso tipo di oggetti. Dietro le quinte, i controller di Kubernetes si preoccupano esclusivamente delle risorse (di altro tipo) collegate alla risorsa primaria da essi controllata.
Per esempio, si possono avere Deployment e Job; entrambe creano Pod. Il Job controller non distrugge i Pod creati da un Deployment, perché ci sono informazioni (labels) che vengono usate dal controller per distinguere i Pod.
I modi per eseguire i controller
Kubernetes annovera un insieme di controller nativi che sono in esecuzione all'interno del kube-controller-manager. Questi controller nativi forniscono importanti funzionalità di base.
Il Deployment controller ed il Job controller sono esempi di controller che vengono forniti direttamente da Kubernetes stesso (ovvero controller "nativi"). Kubernetes consente di eseguire un piano di controllo(control plane) resiliente, di modo che se un dei controller nativi dovesse fallire, un'altra parte del piano di controllo si occuperà di eseguire quel lavoro.
Al fine di estendere Kubernetes, si possono avere controller in esecuzione al di fuori del piano di controllo. Oppure, se si desidera, è possibile scriversi un nuovo controller. È possibile eseguire il proprio controller come una serie di Pod, oppure esternamente rispetto a Kubernetes. Quale sia la soluzione migliore, dipende dalla responsabilità di un dato controller.
Voci correlate
- Leggi in merito Kubernetes control plane
- Scopri alcune delle basi degli oggetti di Kubernetes
- Per saperne di più riguardo alle API di Kubernetes
- Se vuoi creare un tuo controller, guarda i modelli per l'estensibilità in Estendere Kubernetes.