This the multi-page printable view of this section. Click here to print.
Arquitetura do Kubernetes
1 - Comunicação entre Nó e Control Plane
Este documento cataloga os caminhos de comunicação entre o control plane (o apiserver) e o cluster Kubernetes. A intenção é permitir que os usuários personalizem sua instalação para proteger a configuração de rede então o cluster pode ser executado em uma rede não confiável (ou em IPs totalmente públicos em um provedor de nuvem).
Nó para o Control Plane
Todos os caminhos de comunicação do cluster para o control plane terminam no apiserver (nenhum dos outros componentes do control plane são projetados para expor Serviços remotos). Em uma implantação típica, o apiserver é configurado para escutar conexões remotas em uma porta HTTPS segura (443) com uma ou mais clientes autenticação habilitado. Uma ou mais formas de autorização deve ser habilitado, especialmente se requisições anônimas ou tokens da conta de serviço são autorizados.
Os nós devem ser provisionados com o certificado root público para o cluster de tal forma que eles podem se conectar de forma segura ao apiserver junto com o cliente válido credenciais. Por exemplo, em uma implantação padrão do GKE, as credenciais do cliente fornecidos para o kubelet estão na forma de um certificado de cliente. Vejo bootstrapping TLS do kubelet para provisionamento automatizado de certificados de cliente kubelet.
Os pods que desejam se conectar ao apiserver podem fazê-lo com segurança, aproveitando
conta de serviço para que o Kubernetes injetará automaticamente o certificado raiz público
certificado e um token de portador válido no pod quando ele é instanciado.
O serviço kubernetes (no namespace default) é configurado com um IP virtual
endereço que é redirecionado (via kube-proxy) para o endpoint com HTTPS no
apiserver.
Os componentes do control plane também se comunicam com o apiserver do cluster através da porta segura.
Como resultado, o modo de operação padrão para conexões do cluster (nodes e pods em execução nos Nodes) para o control plane é protegido por padrão e pode passar por redes não confiáveis e/ou públicas.
Control Plane para o nó
Existem dois caminhos de comunicação primários do control plane (apiserver) para os nós. O primeiro é do apiserver para o processo do kubelet que é executado em cada nó no cluster. O segundo é do apiserver para qualquer nó, pod, ou serviço através da funcionalidade de proxy do apiserver.
apiserver para o kubelet
As conexões do apiserver ao kubelet são usadas para:
- Buscar logs para pods.
- Anexar (através de kubectl) pods em execução.
- Fornecer a funcionalidade de encaminhamento de porta do kubelet.
Essas conexões terminam no endpoint HTTPS do kubelet. Por padrão, o apiserver não verifica o certificado de serviço do kubelet, o que torna a conexão sujeita a ataques man-in-the-middle, o que o torna inseguro para passar por redes não confiáveis e / ou públicas.
Para verificar essa conexão, use a flag --kubelet-certificate-authority para
fornecer o apiserver com um pacote de certificado raiz para usar e verificar o
certificado de serviço da kubelet.
Se isso não for possível, use o SSH túnel entre o apiserver e kubelet se necessário para evitar a conexão ao longo de um rede não confiável ou pública.
Finalmente, Autenticação e/ou autorização do Kubelet deve ser ativado para proteger a API do kubelet.
apiserver para nós, pods e serviços
As conexões a partir do apiserver para um nó, pod ou serviço padrão para simples
conexões HTTP não são autenticadas nem criptografadas. Eles
podem ser executados em uma conexão HTTPS segura prefixando https: no nó,
pod, ou nome do serviço no URL da API, mas eles não validarão o certificado
fornecido pelo ponto de extremidade HTTPS, nem fornece credenciais de cliente, enquanto
a conexão será criptografada, não fornecerá nenhuma garantia de integridade.
Estas conexões não são atualmente seguras para serem usados por redes não confiáveis e/ou públicas.
SSH Túnel
O Kubernetes suporta túneis SSH para proteger os caminhos de comunicação do control plane para os nós. Nesta configuração, o apiserver inicia um túnel SSH para cada nó no cluster (conectando ao servidor ssh escutando na porta 22) e passa todo o tráfego destinado a um kubelet, nó, pod ou serviço através do túnel. Este túnel garante que o tráfego não seja exposto fora da rede aos quais os nós estão sendo executados.
Atualmente, os túneis SSH estão obsoletos, portanto, você não deve optar por usá-los, a menos que saiba o que está fazendo. O serviço Konnectivity é um substituto para este canal de comunicação.
Konnectivity service
Kubernetes v1.18 [beta]Como uma substituição aos túneis SSH, o serviço Konnectivity fornece proxy de nível TCP para a comunicação do control plane para o cluster. O serviço Konnectivity consiste em duas partes: o servidor Konnectivity na rede control plane e os agentes Konnectivity na rede dos nós. Os agentes Konnectivity iniciam conexões com o servidor Konnectivity e mantêm as conexões de rede. Depois de habilitar o serviço Konnectivity, todo o tráfego do control plane para os nós passa por essas conexões.
Veja a tarefa do Konnectivity para configurar o serviço Konnectivity no seu cluster.
2 - Conceitos sobre Cloud Controller Manager
O conceito do Cloud Controller Manager (CCM) (não confundir com o binário) foi originalmente criado para permitir que o código específico de provedor de nuvem e o núcleo do Kubernetes evoluíssem independentemente um do outro. O Cloud Controller Manager é executado junto com outros componentes principais, como o Kubernetes controller manager, o servidor de API e o scheduler. Também pode ser iniciado como um addon do Kubernetes, caso em que é executado em cima do Kubernetes.
O design do Cloud Controller Manager é baseado em um mecanismo de plug-in que permite que novos provedores de nuvem se integrem facilmente ao Kubernetes usando plug-ins. Existem planos para integrar novos provedores de nuvem no Kubernetes e para migrar provedores de nuvem que estão utilizando o modelo antigo para o novo modelo de CCM.
Este documento discute os conceitos por trás do Cloud Controller Manager e fornece detalhes sobre suas funções associadas.
Aqui está a arquitetura de um cluster Kubernetes sem o Cloud Controller Manager:
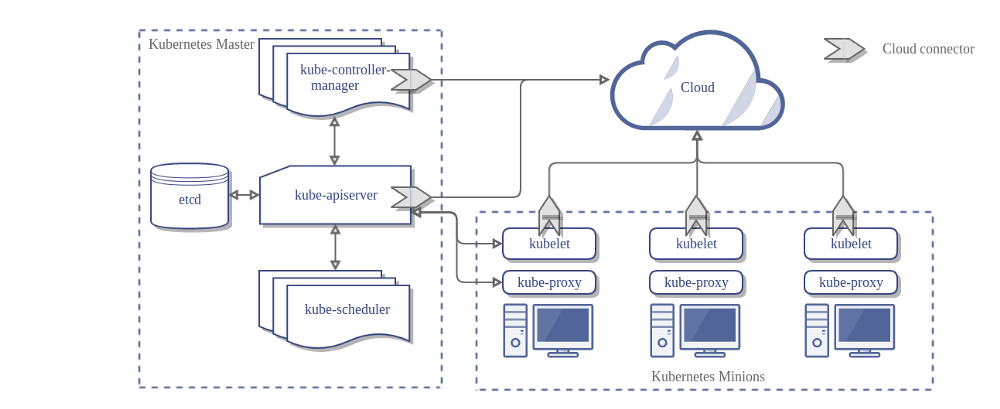
Projeto de Arquitetura (Design)
No diagrama anterior, o Kubernetes e o provedor de nuvem são integrados através de vários componentes diferentes:
- Kubelet
- Kubernetes controller manager
- Kubernetes API server
O CCM consolida toda a lógica que depende da nuvem dos três componentes anteriores para criar um único ponto de integração com a nuvem. A nova arquitetura com o CCM se parece com isso:
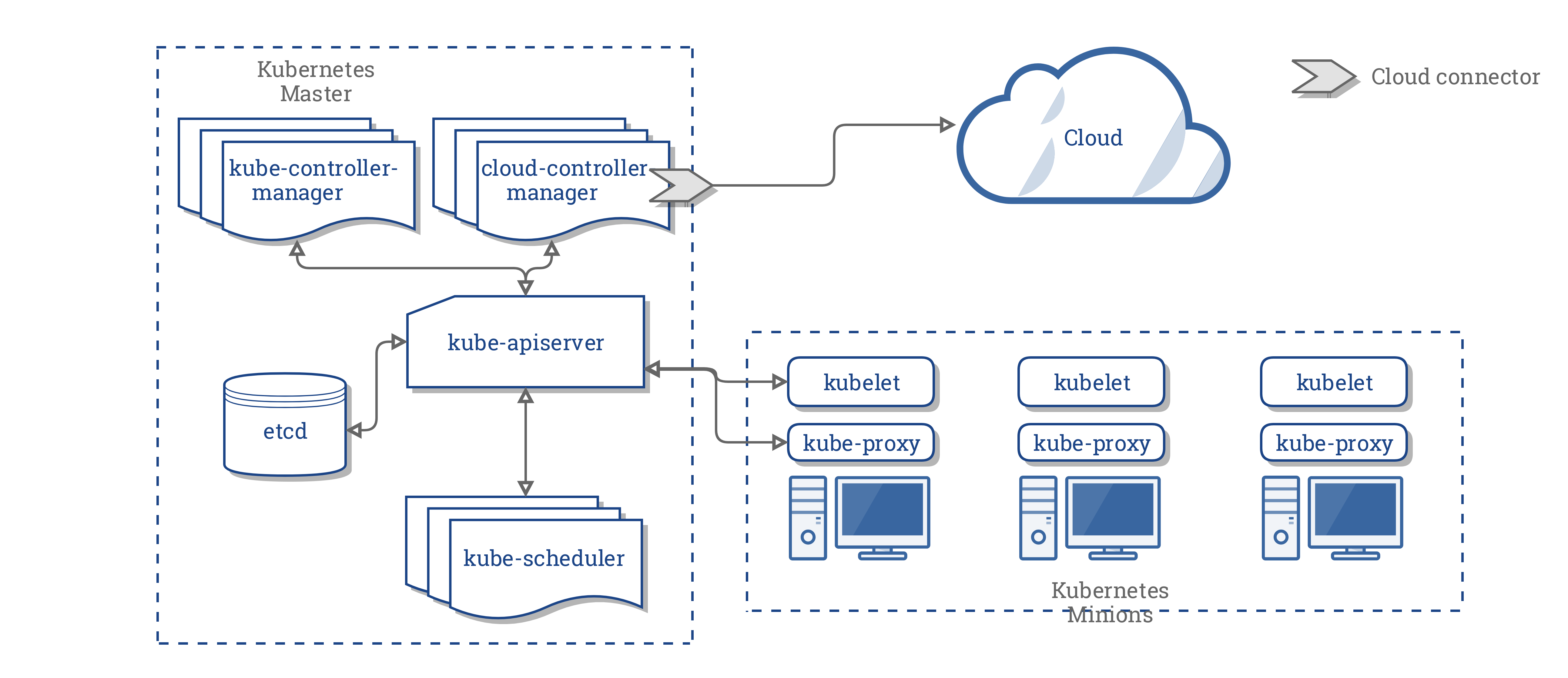
Componentes do CCM
O CCM separa algumas das funcionalidades do KCM (Kubernetes Controller Manager) e o executa como um processo separado. Especificamente, isso elimina os controladores no KCM que dependem da nuvem. O KCM tem os seguintes loops de controlador dependentes de nuvem:
- Node controller
- Volume controller
- Route controller
- Service controller
Na versão 1.9, o CCM executa os seguintes controladores da lista anterior:
- Node controller
- Route controller
- Service controller
Note: O Volume Controller foi deliberadamente escolhido para não fazer parte do CCM. Devido à complexidade envolvida e devido aos esforços existentes para abstrair a lógica de volume específica do fornecedor, foi decidido que o Volume Controller não será movido para o CCM.
O plano original para suportar volumes usando o CCM era usar volumes Flex para suportar volumes plugáveis. No entanto, um esforço concorrente conhecido como CSI está sendo planejado para substituir o Flex.
Considerando essas dinâmicas, decidimos ter uma medida de intervalo intermediário até que o CSI esteja pronto.
Funções do CCM
O CCM herda suas funções de componentes do Kubernetes que são dependentes de um provedor de nuvem. Esta seção é estruturada com base nesses componentes.
1. Kubernetes Controller Manager
A maioria das funções do CCM é derivada do KCM. Conforme mencionado na seção anterior, o CCM executa os seguintes ciclos de controle:
- Node Controller
- Route Controller
- Service Controller
Node Controller
O Node Controller é responsável por inicializar um nó obtendo informações sobre os nós em execução no cluster do provedor de nuvem. O Node Controller executa as seguintes funções:
- Inicializar um node com labels de região/zona específicos para a nuvem.
- Inicialize um node com detalhes de instância específicos da nuvem, por exemplo, tipo e tamanho.
- Obtenha os endereços de rede e o nome do host do node.
- No caso de um node não responder, verifique a nuvem para ver se o node foi excluído da nuvem. Se o node foi excluído da nuvem, exclua o objeto Node do Kubernetes.
Route Controller
O Route Controller é responsável por configurar as rotas na nuvem apropriadamente, de modo que os contêineres em diferentes nodes no cluster do Kubernetes possam se comunicar entre si. O Route Controller é aplicável apenas para clusters do Google Compute Engine.
Service controller
O Service controller é responsável por ouvir os eventos de criação, atualização e exclusão do serviço. Com base no estado atual dos serviços no Kubernetes, ele configura os balanceadores de carga da nuvem (como o ELB, o Google LB ou o Oracle Cloud Infrastrucutre LB) para refletir o estado dos serviços no Kubernetes. Além disso, garante que os back-ends de serviço para balanceadores de carga da nuvem estejam atualizados.
2. Kubelet
O Node Controller contém a funcionalidade dependente da nuvem do kubelet. Antes da introdução do CCM, o kubelet era responsável por inicializar um nó com detalhes específicos da nuvem, como endereços IP, rótulos de região / zona e informações de tipo de instância. A introdução do CCM mudou esta operação de inicialização do kubelet para o CCM.
Nesse novo modelo, o kubelet inicializa um nó sem informações específicas da nuvem. No entanto, ele adiciona uma marca (taint) ao nó recém-criado que torna o nó não programável até que o CCM inicialize o nó com informações específicas da nuvem. Em seguida, remove essa mancha (taint).
Mecanismo de plugins
O Cloud Controller Manager usa interfaces Go para permitir implementações de qualquer nuvem a ser conectada. Especificamente, ele usa a Interface CloudProvider definidaaqui.
A implementação dos quatro controladores compartilhados destacados acima, e algumas estruturas que ficam junto com a interface compartilhada do provedor de nuvem, permanecerão no núcleo do Kubernetes. Implementações específicas para provedores de nuvem serão construídas fora do núcleo e implementarão interfaces definidas no núcleo.
Para obter mais informações sobre o desenvolvimento de plug-ins, consulteDesenvolvendo o Cloud Controller Manager.
Autorização
Esta seção divide o acesso necessário em vários objetos da API pelo CCM para executar suas operações.
Node Controller
O Node Controller só funciona com objetos Node. Ele requer acesso total para obter, listar, criar, atualizar, corrigir, assistir e excluir objetos Node.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Rote Controller
O Rote Controller escuta a criação do objeto Node e configura as rotas apropriadamente. Isso requer acesso a objetos Node.
v1/Node:
- Get
Service Controller
O Service Controller escuta eventos de criação, atualização e exclusão de objeto de serviço e, em seguida, configura pontos de extremidade para esses serviços de forma apropriada.
Para acessar os Serviços, é necessário listar e monitorar o acesso. Para atualizar os Serviços, ele requer patch e atualização de acesso.
Para configurar endpoints para os Serviços, é necessário acesso para criar, listar, obter, assistir e atualizar.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Outros
A implementação do núcleo do CCM requer acesso para criar eventos e, para garantir a operação segura, requer acesso para criar ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
O RBAC ClusterRole para o CCM se parece com isso:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Implementações de Provedores de Nuvem
Os seguintes provedores de nuvem implementaram CCMs:
Administração de Cluster
Voce vai encontrar instruções completas para configurar e executar o CCM aqui.
3 - Controladores
Em robótica e automação um control loop, ou em português ciclo de controle, é um ciclo não terminado que regula o estado de um sistema.
Um exemplo de ciclo de controle é um termostato de uma sala.
Quando você define a temperatura, isso indica ao termostato sobre o seu estado desejado. A temperatura ambiente real é o estado atual. O termostato atua de forma a trazer o estado atual mais perto do estado desejado, ligando ou desligando o equipamento.
No Kubernetes, controladores são ciclos de controle que observam o estado do seu cluster, e então fazer ou requisitar mudanças onde necessário. Cada controlador tenta mover o estado atual do cluster mais perto do estado desejado.Padrão Controlador (Controller pattern)
Um controlador rastreia pelo menos um tipo de recurso Kubernetes. Estes objetos têm um campo spec que representa o estado desejado. O(s) controlador(es) para aquele recurso são responsáveis por trazer o estado atual mais perto do estado desejado.
O controlador pode executar uma ação ele próprio, ou, o que é mais comum, no Kubernetes, o controlador envia uma mensagem para o API server (servidor de API) que tem efeitos colaterais úteis. Você vai ver exemplos disto abaixo.
Controlador via API server
O controlador Job é um exemplo de um controlador Kubernetes embutido. Controladores embutidos gerem estados através da interação com o cluster API server.
Job é um recurso do Kubernetes que é executado em um Pod, ou talvez vários Pods, com o objetivo de executar uma tarefa e depois parar.
(Uma vez agendado, objetos Pod passam a fazer parte do estado desejado para um kubelet.
Quando o controlador Job observa uma nova tarefa ele garante que, algures no seu cluster, os kubelets num conjunto de nós (Nodes) estão correndo o número correto de Pods para completar o trabalho. O controlador Job não corre Pods ou containers ele próprio. Em vez disso, o controlador Job informa o API server para criar ou remover Pods. Outros componentes do plano de controle (control plane) atuam na nova informação (existem novos Pods para serem agendados e executados), e eventualmente o trabalho é feito.
Após ter criado um novo Job, o estado desejado é que esse Job seja completado. O controlador Job faz com que o estado atual para esse Job esteja mais perto do seu estado desejado: criando Pods que fazem o trabalho desejado para esse Job para que o Job fique mais perto de ser completado.
Controladores também atualizam os objetos que os configuram.
Por exemplo: assim que o trabalho de um Job está completo,
o controlador Job atualiza esse objeto Job para o marcar como Finished (terminado).
(Isto é um pouco como alguns termostatos desligam uma luz para indicar que a temperatura da sala está agora na temperatura que foi introduzida).
Controle direto
Em contraste com Job, alguns controladores necessitam de efetuar mudanças fora do cluster.
Por exemplo, se usar um ciclo de controle para garantir que existem Nodes suficientes no seu cluster, então esse controlador necessita de algo exterior ao cluster atual para configurar novos Nodes quando necessário.
Controladores que interagem com estados externos encontram o seu estado desejado a partir do API server, e então comunicam diretamente com o sistema externo para trazer o estado atual mais próximo do desejado.
(Existe um controlador que escala horizontalmente nós no seu cluster. Veja Escalamento automático do cluster)
Estado desejado versus atual
Kubernetes tem uma visão cloud-native de sistemas e é capaz de manipular mudanças constantes.
O seu cluster pode mudar em qualquer momento à medida que as ações acontecem e os ciclos de controle corrigem falhas automaticamente. Isto significa que, potencialmente, o seu cluster nunca atinge um estado estável.
Enquanto os controladores no seu cluster estiverem rodando e forem capazes de fazer alterações úteis, não importa se o estado é estável ou se é instável.
Design
Como um princípio do seu desenho, o Kubernetes usa muitos controladores onde cada um gerencia um aspecto particular do estado do cluster. Comumente, um particular ciclo de controle (controlador) usa uma espécie de recurso como o seu estado desejado, e tem uma espécie diferente de recurso que o mesmo gere para garantir que esse estado desejado é cumprido.
É útil que haja controladores simples em vez de um conjunto monolítico de ciclos de controle que estão interligados. Controladores podem falhar, então o Kubernetes foi desenhado para permitir isso.
Por exemplo: um controlador de Jobs rastreia objetos Job (para descobrir novos trabalhos) e objetos Pod (para correr o Jobs, e então ver quando o trabalho termina). Neste caso outra coisa cria os Jobs, enquanto o controlador Job cria Pods.
Note:Podem existir vários controladores que criam ou atualizam a mesma espécie (kind) de objeto. Atrás das cortinas, os controladores do Kubernetes garantem que eles apenas tomam atenção aos recursos ligados aos seus recursos controladores.
Por exemplo, você pode ter Deployments e Jobs; ambos criam Pods. O controlador de Job não apaga os Pods que o seu Deployment criou, porque existe informação (labels) que os controladores podem usar para diferenciar esses Pods.
Formas de rodar controladores
O Kubernetes vem com um conjunto de controladores embutidos que correm dentro do kube-controller-manager. Estes controladores embutidos providenciam comportamentos centrais importantes.
O controlador Deployment e o controlador Job são exemplos de controladores que veem como parte do próprio Kubernetes (controladores "embutidos"). O Kubernetes deixa você correr o plano de controle resiliente, para que se qualquer um dos controladores embutidos falhar, outra parte do plano de controle assume o trabalho.
Pode encontrar controladores fora do plano de controle, para extender o Kubernetes. Ou, se quiser, pode escrever um novo controlador você mesmo. Pode correr o seu próprio controlador como um conjunto de Pods, ou externo ao Kubernetes. O que encaixa melhor vai depender no que esse controlador faz em particular.
What's next
- Leia mais sobre o plano de controle do Kubernetes
- Descubra alguns dos objetos Kubernetes básicos.
- Aprenda mais sobre API do Kubernetes
- Se pretender escrever o seu próprio controlador, veja Padrões de Extensão